OpenCL Fast Fourier Transform
Eric Bainville - May 2010Benchmarking the radix-r kernels
Let's benchmark our OpenCL kernels using the best variants of the code for each board. On the GTX285, use a mix of radix-2, radix-4 variant C, and radix-8 variant B, all with native sin+cos. On the HD5870, use a mix of radix-2, radix-4 variant A, radix-8 variant A, and optionally radix-16, all with native sin+cos. We disabled OpenCL kernel profiling to get the best running times. I tried several variants (in max radix, code variant, sin+cos) and reported the lowest time reached for each N.
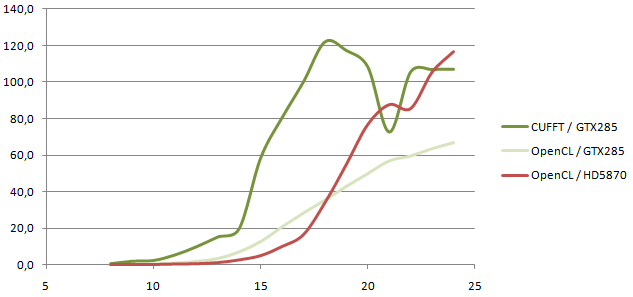
The multi-kernel with no shared memory approach provides good levels of performance on the ATI HD5870, matching CUFFT on the GTX285 for large dimensions.
Even more interesting are the performances measured including host-device transferts. This is what matters to the user, unless more pre- or post- processing of the data is executed on the GPU too.
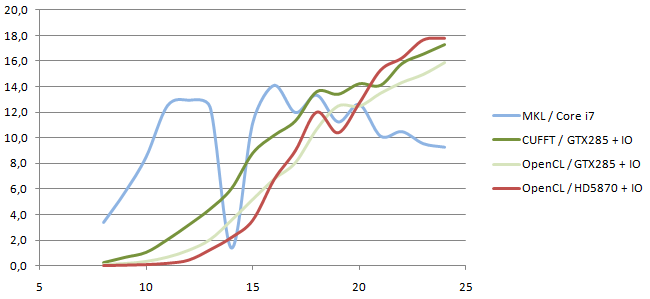
- When data is not already in the GPU, the data transfert bottleneck makes the GPU less efficient than the CPU for small problem sizes, here N<218.
- Running several times simple kernels not using local memory is a viable alternative to longer kernels communicating through local memory.
- The ATI HD5870 can outperform the NVidia GTX285 running CUFFT in the studied case. Both cards have a comparable memory bandwidth, and the HD5870 has a higher computing power.
In the next page, we will allocate all threads of a single work group to the computation of a larger radix transformation: One work-group per DFT (1).
| OpenCL FFT (OLD) : Radix 4,8,16,32 kernels | Top of Page | OpenCL FFT (OLD) : One work-group per DFT (1) |
