GPU matrix-vector product (gemv)
Eric Bainville - Feb 2010Conclusions
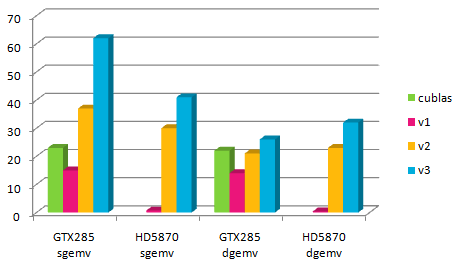
Performance (GFlops) of the various algorithms in single (sgemv) and
double (dgemv) precision.
- The wrong memory access pattern can kill the performance of a kernel.
- All memory access optimizations, like broadcast, may not be present on all devices.
- Although not specified in the OpenCL standard, the order of dimensions has an influence on how threads are put together to form warps or wavefronts, which in turns has a significant impact on memory access patterns.
- Splitting an operation into several kernels may allow a better use of the hardware.
- Despite some cases of catastrophic memory access for the HD5870, both the HD5870 and GTX285 have comparable performance, with an advantage to the ATI GPU for double precision computations and memory access.
| OpenCL GEMV : Two kernels | Top of Page | OpenCL Multiprecision |
