How fast can we compute 1D gradient?
Eric Bainville - Oct 2009SSE instructions
16-bytes aligned moves can be handled efficiently with movaps at 0.5 cycles/float. This speed is reached by the memcpy function of the VS2008 C runtime (msvcr90). In the case of a one element shift, the output is no more aligned on 16-byte addresses. In this case, memcpy(out+1,in,(n-1)*sizeof(float)) runs at 1.1 cycles/float. memcpy calls the movs instruction.
We are manipulating 128-bit packed vectors of 4 single precision floating point numbers, corresponding to the "PS" (packed single) suffix for the SIMD instructions. To move floats around without modifying them, we can use the following instructions:
MOVAPS
Copies an XMM register to another XMM register, or read/write 4 float between memory (at a 16-byte aligned address) and an XMM register.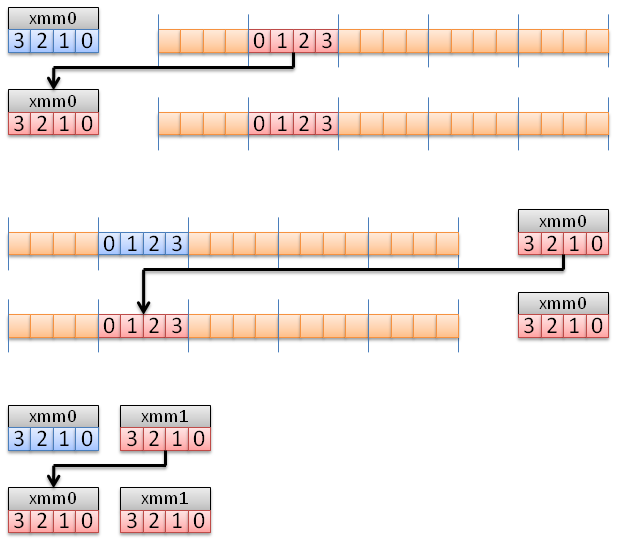
When loading float x[4] into an XMM register, x[0] is copied in bits 0-31, x[1] in bits 32-64, etc. In our diagrams, registers are represented with the MSB to the left (bit 127), the same convention is used in AMD and Intel reference manuals.
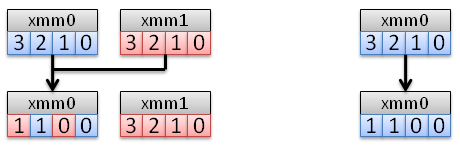
UNPCKLPS / UNPCKHPS
Unpacks the low or high half of two XMM registers into on XMM register.
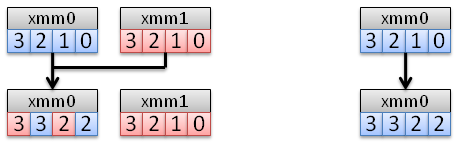
SHUFPS
Selects any two elements of the destination XMM register and move them in the lower half of it, and selects any two elements of the source XMM register and move them in the upper half of the destination.
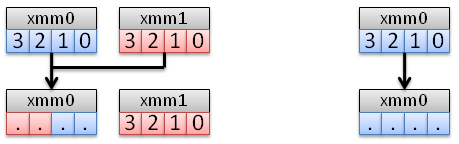
We can now solve our first SSE puzzle: SSE vector right shift.
| SSE gradient : C implementation | Top of Page | SSE gradient : SSE right shift |
