GPU Benchmarks
Eric Bainville - Nov 2009Memory operations
Memory copy
Copy from host memory to device buffer is done by a call to clEnqueueWriteBuffer, and copy from device buffer to host memory by a call to clEnqueueReadBuffer. In both cases, data transits on the PCI Express bus. The PCI Express x16 Gen2 bus has a bandwidth of 8 GB/s.
Copy between two device (GPU) buffers is done by a call to clEnqueueCopyBuffer. The available memory bandwidth in the GTX285 is 158 GB/s, and 153 GB/s for the HD5870. Since copy requires two memory accesses (read+write), the maximum speed we can hope to reach for a copy is nearly 80 GB/s for both cards. We measure speed by MB of output computed per second.
See the NVIDIA OpenCL Best Practices Guide on NVIDIA developer site for more details about memory bandwidth calculations and memory optimization. AMD site now provides similar documents: AMD OpenCL zone.
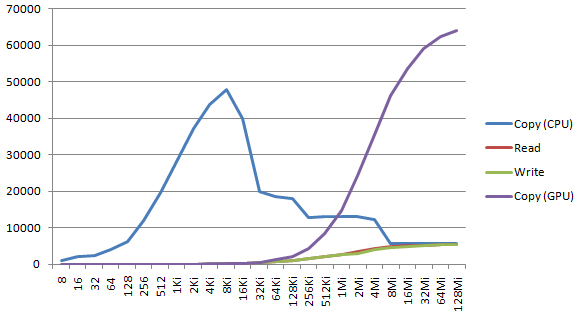
Copy between two host (CPU) buffers is done by a call to CopyMemory (Windows) or memcpy (Linux). Each copy is repeated a large number of times, allowing the data to stay in cache if possible. The various CPU cache levels and virtual memory management layers introduce several levels of performance: each time a cache level is saturated; speed is reduced as we interact with the next level of cache.
The graph below shows the throughput (in MB of output computed per second) for blocks of 2p bytes, from 8B to 128MiB.
The best measured values for GPU devices are:
| Operation | GTX285 Linux | GTX285 Windows | HD5870 Linux | HD5870 Windows |
|---|---|---|---|---|
| Host to Device | 2.8 GB/s | 5.0 GB/s | (to update) | 3.7 GB/s |
| Device to Host | 2.5 GB/s | 5.0 GB/s | (to update) | 2.7 GB/s |
| Device to Device | 65 GB/s | 65 GB/s | (to update) | 63 GB/s |
The call overhead to invoke the OpenCL driver is significant: it is more efficient to copy large buffers. For large buffers, we almost reach the theoretical bandwidth for device-device copy. As expected, speed of host-device copy is limited by the bus bandwidth, and such these transferts should be reduced to the minimum.
For the CPU memory copy, the top speed at 48 GB/s below 16KiB correspond to the L1 cache (input and output arrays fit in the L1 cache), the plateau 32KiB-128KiB at 18 GB/s corresponds to the L2 cache, the plateau 256KiB-4MiB at 13 GB/s to the L3 cache, and the last plateau at 5.6 GB/s to the external memory access.
The CPU values measured here are for one single thread, and correspond to memory bandwidth of 96, 36, 26, 11 GB/s for each level (L1, L2, L3, ext). The CPU has 4 cores and 2 threads per core. The available memory bandwidth is used at its full potential when more threads are running. SiSoftware Sandra reports these values for 8 threads: 343, 172, 48, 15 GB/s (converted from reported GiB/s).
Let's experiment this ourselves on the memory copy operation. Copy is now done independently in T threads. Each thread processes a block of size 1/T of the full block. The measured timings are the following (the thread creation/join/deletion is not counted):
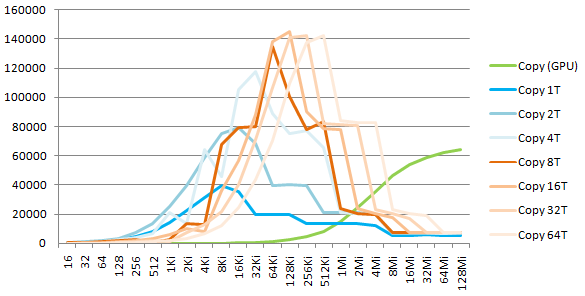
We observe that the memory subsystem of the CPU reaches its full potential when the CPU is "saturated" by threads accessing disjoint memory areas. The measured total bandwidth (Read+Write) is 284, 162, 40, 14 GB/s for L1, L2, L3, and ext levels.
The next graph shows the measured memory copy performance on all systems. For the CPU values, we take the best value reached while the number of threads varies from 1 to 16, for each total block size between 1 KiB and 512 Mib.
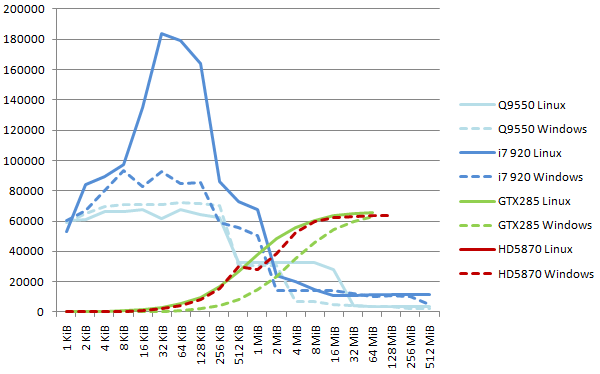
We see the high efficiency of the glibc memcpy under Linux for the Core i7. At 183 GB/s each core reads and writes from/to L1 cache an average of 13.7 bytes per cycle, with a theoretical max of 16 bytes per cycles (using movaps or similar SSE instructions). The Windows library (CopyMemory) only reaches half this throughput.
Another point to note on this diagram is the difference in driver efficiency between Linux and Windows for the GTX285 board: the Linux curves rises earlier, meaning the latency of a call to clEnqueueCopyBuffer is much lower on Linux. At the end of the curve, the "asymptotic speed" (pure copy speed) is the same, at 66 GB/s as seen earlier.
The 2.0 and then 2.01 and 2.1 AMD OpenCL drivers vastly improved host/device and device/device memory throughput over previous versions, and they are now comparable to NVidia values.
Memory zero
This operation sets to 0 all elements of a memory block. Since there is no dedicated function to clear the memory in the GPU, we need to run a kernel to set the values. Let's start with the simplest code:
__kernel void zero(__global long * a)
{
int i = get_global_id(0);
a[i] = 0;
}
N instances of the kernel (one per word) are executed by a call to clEnqueueNDRangeKernel.
The graph below shows the throughput (in MB/s) for blocks of 2p bytes, from 16B to 128MiB. For the GPU zero, I tried various word sizes: 16-bit (short), 32-bit (int), 64-bit (long), 128-bit (float4).
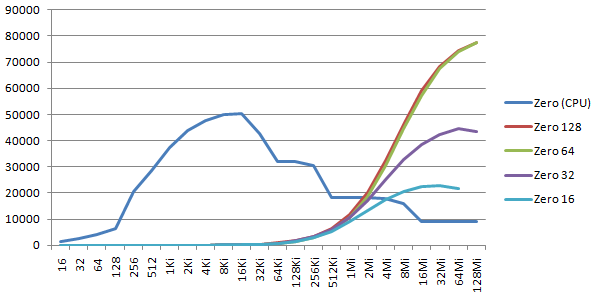
The peak GPU speed is 77 GB/s, reached for words of 64 and 128 bits. Smaller words have less efficient memory access, and speed is 66% or 33% of the 64-bit speed.
CPU ZeroMemory calls show very well the various levels of cache: 50 GB/s for the L1 cache, 32 GB/s for the L2 cache, 18 GB/s for the L3 cache, and 9 GB/s external memory access.
As with memory copy, we can divide the calls to ZeroMemory into T threads, and see how the CPU manages parallel memory zero:
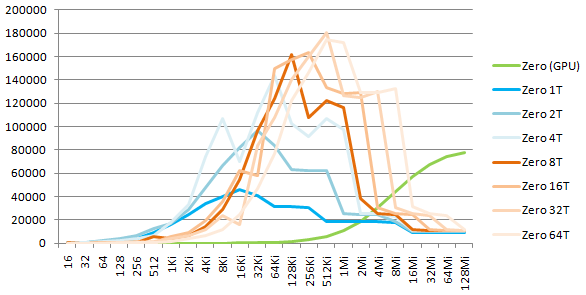
Here again, we observe that the memory subsystem of the CPU is really efficient under multithread load. The mesured total bandwidth (Write) is 163, 126, 24, 11 GB/s for L1, L2, L3, and ext levels.
As we did before for the copy, the next graph shows the measured memory copy performance on all systems. We report the max measured value for each block size, for various values of the number of threads (CPU) or the workgroup size (GPU).
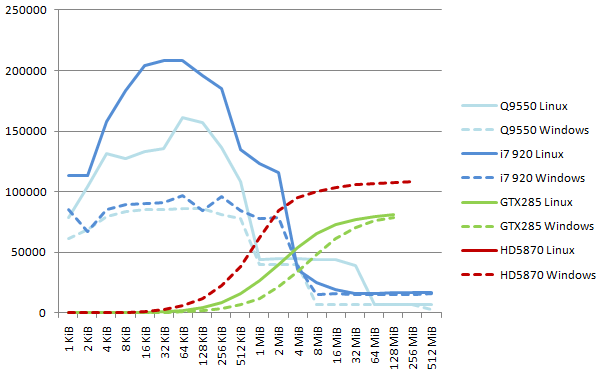
As with the copy, the GNU C Library does an excellent job and reaches 208 GB/s, corresponding to 15.6 bytes per clock cycle and per core: the write capacity of the CPU is used at 97% when accessing the L1 cache! Here again the NVidia Linux driver offers a lower latency than its Windows counterpart, and both reach 81 GB/s for the larger blocks. The new drivers allow the ATI board to reach an impressive 108 GB/s.
Conclusions on memory operations
- the cache hierarchy of the CPU makes it much more efficient than the GPU for memory blocks of small to moderate size (less than 1 MiB);
- to use the CPU cache hierarchy at its full potential, all threads (here 8 or more) of the CPU must be used;
- for larger blocks, the superior physical memory interface of the GPU is an advantage (x6 factor);
- host to device transferts run at relatively low speed, and should be avoided.
In the next section we will introduce a redundant large number representation, and see how fast we can add two large numbers.
| GPU Benchmarks : Introduction | Top of Page | GPU Benchmarks : Addition |
